Online Data#
The internet is probably the most common place to seek information. In fact, every homepage you browse and every article you read is data and, as long as there is no pay wall or other security feature, free to you. Most of the data in such form is unordered and cannot easily be analysed quantitatively, like text or video clips (especially text usually does carry a lot of information). Beside this unstructured data, there are files for free to download, e.g. in a .csv format. Yet, all this has to be done by hand: either click some ‘download’ button to acquire a file or, even worse, copy a text online and paste it into a document.
In the next sections, we will at first briefly introduce some basic elements of online communication and then present different ways to access data online from our computer without loading and storing it manually (we will write code manually, though).
Website basics#
HTTP#
The HyperText Transfer Protocol is used for online communication in the world wide web (www). The basic operations are requests and response. In the www, when trying to open a website, you are actually sending a request to a server asking to provide the information stored under that web address. The server will then hopefully respond to your request by sending the respective information to your machine which then will be rendered in your browser. This response information does contain additional meta data, like the time of the request, status/error codes, etc which we will see later. An extension is https (secure).
URL#
The Uniform Resource Locator is the address your request is telling the server to look for information. It consists of several elements, http://www.uni-passau.de:
the protocol: usually
httporhttpsin the www, followed by a colon and doube slash://the hostname:
www.uni-passau.dea path/query: appended with
/or?to the hostname
To know about these three separate parts enables us to automate navigation in the www using python.
HTML#
Information in the www is usually found in the HyperText Markup Language for web browsers. HTML uses tags to structure hierarchical data, telling the browser how to display the single elements. Tags appear in pairs and are enclosed in angle brackets <tag> to open a respective section and </tag> to close it.
Any HTML will be enclosed in the most outer <html> and </html> tags. Inside this, the document is structured by various tags. To name just some:
<body>: the main part of a website containing the displayed information<div>: division, denotes a section<p>: paragraph, simple text information<table>: displays data in a table, (<tr>for single rows)<b>: bold, does not structure the page, but alters the font
Beside the tag itself attributes may be included inside the brackets. With the right tools, we can exploit tags and attributes to navigate to specific elements on webpages in order to extract the element information. Very common attributes are id and class.
A simple html may look like this (inside “”” and indented):
"""
<html>
<body>
<div id='div_1'>
<p class='section' id ='intro'>
This is a brief introduction to <b>HTML</b>.
</p>
</div>
</body>
</html>
"""
"\n<html>\n <body>\n <div id='div_1'>\n <p class='section' id ='intro'>\n This is a brief introduction to <b>HTML</b>.\n </p>\n </div>\n </body>\n</html>\n"
Since jupyter works with html, we can render the above html directly in a markdown cell:
This is a brief introduction to HTML.
JSON#
The JavaScript Object Notation is a type of data format which you will frequently encounter when working with online data. For one, websites that offer a .scv download often also offer a .json file to download. Moreover, the json format is often used by APIs (see next secrtion) to transfer data. Its structure looks is very similar to a python dictionary, using curly and square brackets and key-value pairs as well as enabling nesting. Data is therefore stored in such objects. There are packages which can handle json files, for example pandas to transform it into a dataframe.
Let’s see what a dataframe looks like when transformed into a json format:
import pandas as pd
df = pd.DataFrame([[19, 55], [22, 64]],
index=["obj_1", "obj_2"],
columns=["length", "height"])
df
| length | height | |
|---|---|---|
| obj_1 | 19 | 55 |
| obj_2 | 22 | 64 |
And the respective json format, created with the to_json() method:
print(df.to_json())
{"length":{"obj_1":19,"obj_2":22},"height":{"obj_1":55,"obj_2":64}}
# back to dataframe with read_json()
pd.read_json(df.to_json())
| length | height | |
|---|---|---|
| obj_1 | 19 | 55 |
| obj_2 | 22 | 64 |
API#
Instead of (or in addition to) any downloadable files, data providers may offer an API (Application Programming Interface) to access data. An API constitutes a rather convenient way to getting information as it allows direct machine to machine transaction - meaning you can log in, select and download data directly with and into python. With reliable API access, it is thus not necessary to store the data on your hard drive permanently (you must however do so temporarily).
The two most basic operations when working with an API over http:
GET: send a request and get a response from the server, for example the data you asked for
POST: send information to the API, for example to add data to a database remotely
Many large companies offer APIs for programmers, for example the google maps API is often used on web pages where directions are explained or Twitter offers an API where tweets and meta data are provided. These APIs usually are not free. However, free APIs do exist for many topics of data, see here for example .
Normally, the procedure is to register an e-mail account to get an identification key. This key is needed to use the API from your computer and enables the provider to track your activity. For example, if only n downloads are free per day, too unrestrained a downloading business might even get you kicked or banned. In any case, to work properly with an API, one should read the documentary (or at least parts of it).
In general, we will use the requests package for working with APIs.
For a first and simpler example, though, we can make use of a package called wikipediaapi implementing the Wikipedia API. Whenever working with APIs, it is advised to look for trustworthy implementations, since the work might have been done for you already. We will then go on to produce the same result using the requests package.
As usual, the first step is to import the packages (if already installed).
import wikipediaapi
# instantiate object and call page method
wiki_en = wikipediaapi.Wikipedia('en')
page = wiki_en.page('University_of_Passau')
print('title:\n', page.title)
print('\nsummary:\n',page.summary)
title:
University_of_Passau
summary:
The University of Passau (German: Universität Passau) is a public research university located in Passau, Lower Bavaria, Germany. Founded in 1973, it is the youngest university in Bavaria and consequently has the most modern campus in the state. Nevertheless, its roots as the Institute for Catholic Studies dates back to the early 17th century.
Today it is home to five faculties and 39 different undergraduate and postgraduate degree programmes.
The API from the wikipediaapi package returns preprocessed data from the respective article.
Since APIs may come without such handy packages, we will now engage the requestspackage to perform the same tasks.
At first, we import the package under the alias re.
import requests as re
wiki_url = 'https://en.wikipedia.org/w/api.php'
# store parameters as dictionary to pass to function, may include key and username for authentication
# the parameters are found in the documentary!
params = {'action': 'query',
'format': 'json',
'titles': 'University_of_Passau',
'prop': 'extracts',
'exintro': 1,
'disablelimitreport':1}
response = re.get(wiki_url, params=params)
print(type(response))
<class 'requests.models.Response'>
# check, if request was successful
response.status_code # -> 200
403
Having a successful request, we can now take a look at the response object’s elements. Since the format was specified as json in our request, we can use the built-in .json() method.
To display a json file in a more readbale manner (indents, linebreaks), we can use the json package and its dumpsmethod.
import json
print(json.dumps(response.json(), indent=4))
---------------------------------------------------------------------------
JSONDecodeError Traceback (most recent call last)
File ~/Desktop/Lehre/python_class/venv.nosync/lib/python3.11/site-packages/requests/models.py:976, in Response.json(self, **kwargs)
975 try:
--> 976 return complexjson.loads(self.text, **kwargs)
977 except JSONDecodeError as e:
978 # Catch JSON-related errors and raise as requests.JSONDecodeError
979 # This aliases json.JSONDecodeError and simplejson.JSONDecodeError
File /opt/homebrew/Cellar/python@3.11/3.11.0/Frameworks/Python.framework/Versions/3.11/lib/python3.11/json/__init__.py:346, in loads(s, cls, object_hook, parse_float, parse_int, parse_constant, object_pairs_hook, **kw)
343 if (cls is None and object_hook is None and
344 parse_int is None and parse_float is None and
345 parse_constant is None and object_pairs_hook is None and not kw):
--> 346 return _default_decoder.decode(s)
347 if cls is None:
File /opt/homebrew/Cellar/python@3.11/3.11.0/Frameworks/Python.framework/Versions/3.11/lib/python3.11/json/decoder.py:337, in JSONDecoder.decode(self, s, _w)
333 """Return the Python representation of ``s`` (a ``str`` instance
334 containing a JSON document).
335
336 """
--> 337 obj, end = self.raw_decode(s, idx=_w(s, 0).end())
338 end = _w(s, end).end()
File /opt/homebrew/Cellar/python@3.11/3.11.0/Frameworks/Python.framework/Versions/3.11/lib/python3.11/json/decoder.py:355, in JSONDecoder.raw_decode(self, s, idx)
354 except StopIteration as err:
--> 355 raise JSONDecodeError("Expecting value", s, err.value) from None
356 return obj, end
JSONDecodeError: Expecting value: line 1 column 1 (char 0)
During handling of the above exception, another exception occurred:
JSONDecodeError Traceback (most recent call last)
Cell In [12], line 1
----> 1 print(json.dumps(response.json(), indent=4))
File ~/Desktop/Lehre/python_class/venv.nosync/lib/python3.11/site-packages/requests/models.py:980, in Response.json(self, **kwargs)
976 return complexjson.loads(self.text, **kwargs)
977 except JSONDecodeError as e:
978 # Catch JSON-related errors and raise as requests.JSONDecodeError
979 # This aliases json.JSONDecodeError and simplejson.JSONDecodeError
--> 980 raise RequestsJSONDecodeError(e.msg, e.doc, e.pos)
JSONDecodeError: Expecting value: line 1 column 1 (char 0)
# we can now navigate through the nested dictionaries
title = response.json()['query']['pages']['409091']['title']
print('title: ',title)
summary = response.json()['query']['pages']['409091']['extract']
print('\nsummary:', summary)
title: University of Passau
summary: <p>The <b>University of Passau</b> (<i>Universität Passau</i> in German) is a public research university located in Passau, Lower Bavaria, Germany. Founded in 1973, it is the youngest university in Bavaria and consequently has the most modern campus in the state. Nevertheless, its roots as the Institute for Catholic Studies dates back to the early 17th century.
</p><p>Today it is home to four faculties and 39 different undergraduate and postgraduate degree programmes.</p>
Since the Text is still in html, as can be seen from tags, we are not yet finished. To convert html to normal text, one way is by using BeautifulSoup.
Let’s import it from the bs4 package and transform the html.
from bs4 import BeautifulSoup
# first instantiate object, use 'lxml' parser (installation necessary)
my_soup = BeautifulSoup(summary, 'lxml')
# extract the text, i.e. remove tags
print(my_soup.text)
The University of Passau (Universität Passau in German) is a public research university located in Passau, Lower Bavaria, Germany. Founded in 1973, it is the youngest university in Bavaria and consequently has the most modern campus in the state. Nevertheless, its roots as the Institute for Catholic Studies dates back to the early 17th century.
Today it is home to four faculties and 39 different undergraduate and postgraduate degree programmes.
Website content#
BeautifulSoup can not only extract text from html, but, in analogy to the json dumps() method from before, print html files more readable. We will leverage BeautifulSoup’s functions now to extract again the same information, but now from the website directly, i.e. without an API.
# first, send request - get response from ordinary url
response = re.get('https://en.wikipedia.org/wiki/University_of_Passau')
# second, extract content from the response (html)
html = response.content
# third, instantiate BS onject
soup = BeautifulSoup(html)
# if necessary look at a formatted version of the html
# print(soup.prettify()) # -> very long output
# finally print the text attribute from the created object
print(soup.text[588:1037]) # only part of document for shorter output
The University of Passau (Universität Passau in German) is a public research university located in Passau, Lower Bavaria, Germany. Founded in 1973, it is the youngest university in Bavaria and consequently has the most modern campus in the state. Nevertheless, its roots as the Institute for Catholic Studies dates back to the early 17th century.
Today it is home to four faculties and 39 different undergraduate and postgraduate degree programmes.
soup.find('p').getText()
'The University of Passau (Universität Passau in German) is a public research university located in Passau, Lower Bavaria, Germany. Founded in 1973, it is the youngest university in Bavaria and consequently has the most modern campus in the state. Nevertheless, its roots as the Institute for Catholic Studies dates back to the early 17th century.\n'
We can see, that we loaded the whole website as raw text. One can immediately see that it is not obvious how to extract the wanted summary only. We will later see some ways to extract text and leverage repeated structure across a website for its different pages to extract text sections like this.
Back to APIs#
Now, the API we will mostly use in this course is from financialmodelingprep.com, providing financial and company data. In contrast to the Wikipedia API, a registration by e-mail is required. Please register to get your API key.
To access the data, the key must be submitted in the request. We can use the params statement as before, handing it the respective statements.
(Note that the API key is already saved in “api_key”)
# define components of the request
base_url = 'https://financialmodelingprep.com/api/v3/'
filing = 'profile'
stock = 'GOOG'
params = {'apikey': api_key}
# send request and store reponse
response = re.get(base_url+filing+'/'+stock, params=params)
# Without further processing, the json is already quite well structured to read
response.json()
[{'symbol': 'GOOG',
'price': 101.38,
'beta': 1.099484,
'volAvg': 23226134,
'mktCap': 1316794269696,
'lastDiv': 0.0,
'range': '95.27-152.1',
'changes': -0.01000214,
'companyName': 'Alphabet Inc.',
'currency': 'USD',
'cik': '0001652044',
'isin': 'US02079K1079',
'cusip': '02079K107',
'exchange': 'NASDAQ Global Select',
'exchangeShortName': 'NASDAQ',
'industry': 'Internet Content & Information',
'website': 'https://www.abc.xyz',
'description': 'Alphabet Inc. provides various products and platforms in the United States, Europe, the Middle East, Africa, the Asia-Pacific, Canada, and Latin America. It operates through Google Services, Google Cloud, and Other Bets segments. The Google Services segment offers products and services, including ads, Android, Chrome, hardware, Gmail, Google Drive, Google Maps, Google Photos, Google Play, Search, and YouTube. It is also involved in the sale of apps and in-app purchases and digital content in the Google Play store; and Fitbit wearable devices, Google Nest home products, Pixel phones, and other devices, as well as in the provision of YouTube non-advertising services. The Google Cloud segment offers infrastructure, platform, and other services; Google Workspace that include cloud-based collaboration tools for enterprises, such as Gmail, Docs, Drive, Calendar, and Meet; and other services for enterprise customers. The Other Bets segment sells health technology and internet services. The company was founded in 1998 and is headquartered in Mountain View, California.',
'ceo': 'Mr. Sundar Pichai',
'sector': 'Communication Services',
'country': 'US',
'fullTimeEmployees': '174014',
'phone': '650-253-0000',
'address': '1600 Amphitheatre Parkway',
'city': 'Mountain View',
'state': 'CA',
'zip': '94043',
'dcfDiff': 30.96,
'dcf': 132.35,
'image': 'https://financialmodelingprep.com/image-stock/GOOG.png',
'ipoDate': '2004-08-19',
'defaultImage': False,
'isEtf': False,
'isActivelyTrading': True,
'isAdr': False,
'isFund': False}]
We can also load symbols from all companies listed in the Dow Jones Index and then load historical stock price data from those companies using the afore acquired symbols.
filing = 'dowjones_constituent'
response = re.get(base_url+filing, params=params)
print(response.status_code)
200
dji_df = pd.DataFrame.from_dict(response.json())
print(dji_df.head(3))
symbol name sector \
0 CRM Salesforce.Com Inc Technology
1 WBA Walgreens Boots Alliance Inc Healthcare
2 V Visa Inc Financial Services
subSector headQuarter dateFirstAdded cik \
0 Technology San Francisco, CALIFORNIA 2020-08-31 0001108524
1 Healthcare Deerfield, ILLINOIS 2018-06-26 0001618921
2 Financial Services San Francisco, CALIFORNIA 2013-09-23 0001403161
founded
0 2004-06-23
1 2014-12-31
2 2008-03-19
# extract symbol column and convert to list
dji_symbols = dji_df.symbol.tolist()
print(dji_symbols)
['CRM', 'WBA', 'V', 'NKE', 'UNH', 'TRV', 'VZ', 'INTC', 'WMT', 'JNJ', 'DIS', 'MCD', 'JPM', 'CAT', 'BA', 'AMGN', 'DOW', 'AAPL', 'GS', 'CSCO', 'MSFT', 'HD', 'PG', 'MRK', 'IBM', 'HON', 'KO', 'CVX', 'AXP', 'MMM']
# set the filing (from documentation)
filing = 'historical-price-full'
# create empty dataframe (before loop!) to collect data for every company in loop
dji_hist = pd.DataFrame()
# loop over first 5 symbols in the list
for symbol in dji_symbols[:5]:
# request data for every symbol
response = re.get(base_url+filing+'/'+symbol, params=params)
# break the loop if a response error occurs
if response.status_code != 200:
print('Error! Aborted')
break
# convert the response to json to temporary dataframe
temp_df = pd.DataFrame.from_dict(response.json()['historical'], orient='columns')
# add column with respective symbol
temp_df['symbol'] = symbol
# append temporary dataframe to collect dataframe
dji_hist = pd.concat([dji_hist, temp_df], ignore_index=True)
# delete temporary dataframe before next iteration
del temp_df
# just one example to show all companies' data made it to the collect dataframe: variance of opening price
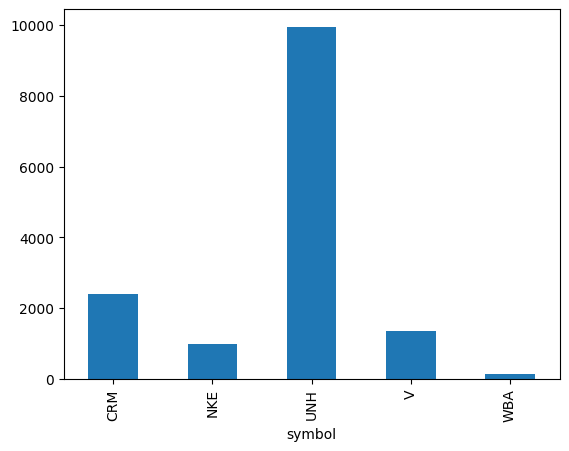
print(dji_hist.groupby('symbol').open.var().plot(kind='bar'))
AxesSubplot(0.125,0.11;0.775x0.77)
We now know how to retrieve data from an API or the whole html content from a normal website. The next chapter will look at how we can extract information displayed on websites in a more directed manner than downloading just all of the website’s content.